收購筆電Lenovo聯晟智達隸屬於全球PC領導廠商聯想集團,致力於打造科技驅動、柔性敏捷、服務體驗一流的智慧物流生態平臺,面向產業端企業提供綜合物流解決方案,成為服務於中國及全球客戶的智慧供應鏈科技企業。聯晟智達大資料團隊逐步引入了多種OLAP分析引擎來更好的滿足需求。DorisDB從眾多的OLAP分析引擎中脫穎而出,它採用了全面向量化的計算技術,是效能非常強悍的新一代MPP資料庫。通過引入DorisDB,構建了全新的統一資料服務平臺,大大降低了資料鏈路開發複雜性,極大提升了BI分析效率。
“作者:韓文博聯想銷售物流大資料平臺負責人,專注於數倉建設、資料分析等領域研究。”
一、OLAP引擎在收購筆電Lenovo聯晟智達的演進史
第一階段
在2018年之前,聯晟智達的資料總量還不是特別大,這個階段使用的是傳統關係型資料庫(SQL Server),資料倉儲體系還尚未建立,很多資料需求的實現都是以SQL指令碼的開發方式來滿足。
但隨著業務複雜度不斷提升,以及資料量的快速增長,這種模式很快遇到了瓶頸。最主要體現在查詢響應時效變得越來越慢。例如:之前執行一個任務需要10分鐘或20分鐘,現在需要一個小時或更長時間,查詢效率嚴重下降。另外資料儲存容量也存在瓶頸,無法滿足隨業務而快速增長的資料量儲存需求。
第二階段
2019年隨著資料倉儲在Hadoop/Hive體系上搭建和完善,ETL任務全部轉移至Hadoop叢集,這個階段使用數十臺Presto完成OLAP分析。Presto天然和Hive共享後設資料資訊,且共同使用物理資料儲存,大量的對數倉表的靈活查詢使用Presto完成。前端BI層面使用Tableau直接連線Presto,實現資料分析與挖掘。
第三階段
2021年聯晟大資料團隊進行了離線數倉的整體設計和搭建,既需要做低延時的BI報表,又要滿足Adhoc複雜查詢,同時對高效明細查詢也有很高的要求。這個階段我們根據場景引入了OLAP圈炙手可熱的DorisDB產品,它既能做Presto的Adhoc多表關聯查詢及複雜巢狀子查詢,又能提供比ClickHouse更好的單表明細查詢和多維物化檢視上卷加速,滿足極速BI分析需求。
二、資料分析體系架構
1.OLAP體系現狀
整個資料分析體系,由資料採集、資料儲存與計算、資料查詢與分析和資料應用組成。
原始架構圖:
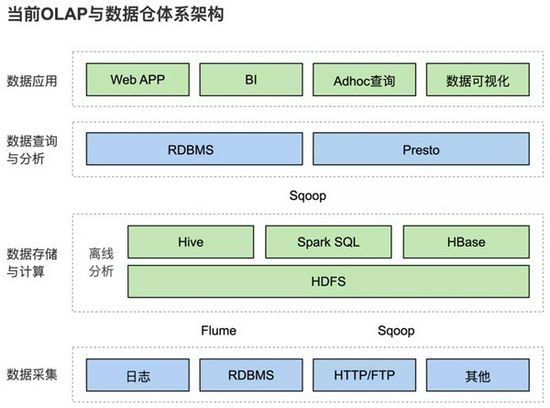
資料採集
1)通過Sqoop讀取RDBMS匯入Hive。
2)用Flume來同步日誌檔案到Hive。
3)通過爬蟲技術將網上資料爬取下來,儲存到RDBMS,再由Sqoop讀取RDBMS,匯入到Hive。
資料儲存與計算
離線資料處理:利用Hive高可擴充套件的批處理能力承擔所有的離線數倉的ETL和資料模型加工的工作。
資料查詢與分析
資料共享層主要提供對外服務的底層資料儲存和查詢共享介面。離線ETL後的資料寫入RDBMS或MPP資料庫中,面向下游多種服務,為Tableau BI、多維固定報表、Adhoc即席查詢等不同場景提供OLAP查詢分析能力。應用側完美服務於BI報表平臺、即席查詢分析平臺及資料視覺化平臺(Control Tower)
資料應用層
資料應用層主要為面向管理和運營人員的報表,查詢要求低時延響應,需求也是迭代層出不窮。面向資料分析師的即席查詢,更是要求OLAP引擎能支援複雜SQL處理、從海量資料中快速遴選資料的能力。
三、各OLAP分析工具選型比較
1.ClickHouse
優點
1)很強的單表查詢效能,適合基於大寬表的OLAP多維分析查詢。
2)包含豐富的MergeTree Family,支援預聚合。
3)非常適合大規模日誌明細資料寫入分析。
缺點
1)不支援真正的刪除與更新。
2)Join方式不是很友好。
3)併發能力比較低。
4)MergeTree合併不完全。
2.DorisDB
優點
1)單表查詢和多表查詢效能都很強,可以同時較好支援寬表查詢場景和複雜多表查詢。
2)支援高併發查詢。
3)支援實時資料微批ETL處理。
4)流式和批量資料寫入都能都比較強。
5)相容MySQL協議和標準SQL。
缺點
1)大規模ETL能力不足。
2)資源隔離還不完善。
四、DorisDB在SEC資料中心的應用實踐
渠道倉配管理(SEC)的核心資料來自兩大塊:一個是消費業務;第二個是SMB中小企業務(Think、揚天)。基於這些資料,根據不同的業務場景需求,彙總出相關業務統計指標,對外提供查詢分析服務。
1。原有解決方案
在引入DorisDB之前,用到大量Hive任務進行業務邏輯清洗加工,清洗加工後的資料部分保留在Hive,部分資料寫入MySQL/SQL Server,以達到資料的落地。前端BI通過Presto計算引擎連線Hive、MysSQL、SQL Server等,實現報表分析及資料視覺化。
2。技術痛點
原有架構主要有以下兩個問題:
1)資料邏輯沒有很好做歸攏合併,維護工作量大,新需求無法快速響應。
2)Presto的在SQL較多的Tableau複雜報表上響應較慢,不能滿足業務即時看數需求。
因此我們希望對原有體系進行優化,核心思路是利用一個OLAP引擎進行這一層的統一,對OLAP引擎的要求是比較高的:
1)能支撐大吞吐量的資料寫入要求。
2)可以支援多維度組合的靈活查詢,響應時效在100ms以下。
3)比較好的支援多表關聯。
4)單表查詢資料量在10億以上,響應時效在100ms以下。
經過大量調研,DorisDB比較契合資料中心的整體要求。DorisDB本身高效的查詢能力,可以為資料中心資料包告提供一體化服務。新架構具備以下優點:
1)結構清晰,RDBMS專注於資料的清洗,業務邏輯計算從Hive遷到DorisDB內實現,DorisDB就是資料業務邏輯的終點。
2)可以維護統一的資料口徑,一份資料輸入,多個APP介面輸出。
3)MPP分散式架構,得以更好的支援分散式聚合和關聯查詢。
4)和Tableau有較好的相容性,可以滿足核心BI分析需求。
3。基於DorisDB的解決方案
升級後架構圖:
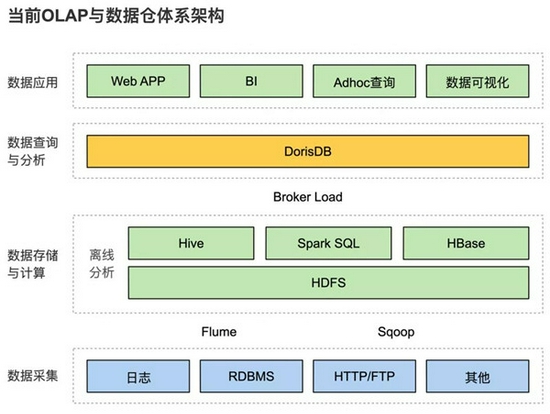
資料表設計
1)資料模型設計
DorisDB本身提供三種資料模型:明細模型/聚合模型/更新模型。對SEC業務來說,目前以明細模型為主,後續如果有其他場景,再考慮應用其他模型。
2)資料分割槽/分桶
DorisDB提供的資料分割槽和分桶功能,可以很好的提升歷史庫存及週轉場景下明細查詢的效能。例如,歷史庫存查詢常見的一種查詢場景,是查詢過去某一時間段內的庫存週轉情況,我們可以在DorisDB中根據出庫時間進行分割槽,過濾掉不必要的分割槽資料,減少整個查詢的資料量進行快速定位,儘量減少了查詢語句所覆蓋的資料範圍,分割槽、分桶、字首索引等能力,可以大大提高點查併發能力。這些特性對業務迎接增長,面對未來可能出現的高併發場景也具有非常大的意義。查詢某一個物料條碼(SN)的歷史軌跡資料,能夠快速的檢索出該條碼的所有歷史出入庫軌跡資訊,幫助我們高效的完成供應鏈全生命週期回溯。
物化檢視
我們利用DorisDB物化檢視能夠實時、按需構建,靈活增加刪除以及透明化使用的特性,建立了基於庫存物料SN粒度、基於產品型別特徵粒度、基於庫房粒度、基於分銷商粒度的物化檢視。基於這些物化檢視,可以極大加速查詢。
資料匯入
資料匯入DorisDB這裡用到了兩種方案:
1)在DorisDB提供的Broker Load基礎上將離線數倉Hive的表匯入到DorisDB中。
2)通過DataX工具,將SQL Server、MySQL上的資料匯入到DorisDB。
4.DorisDB使用效果
靈活建模提升開發效率
結合使用寬表模型和星型模型,寬表和物化檢視可以保證報表效能和併發能力,而星型模型可以讓AP如TP裡那樣建模,直接進行關聯查詢,不必所有場景都依賴寬表準備,在資料一致性和開發效率上得到很好提升。另外,有不少表是在MySQL裡的,我們通過DorisDB外表的方式暴露查詢,省去了資料匯入的過程,大大降低了業務方的開發和遷移週期。DorisDB的分散式Join能力非常強,結合View的能力構建統一的檢視層,面下不同BI報表進行查詢,提升了指標口徑的一致性,降低了重複開發。
BI體驗極好
前期部分BI視覺化是基於SQL Server、MySQL構建的。部分看板不斷優化和豐富需求後,加上多維度靈活條件篩選,每次載入很慢,有些Tableau報表很長時間才能載入出來,業務無法接受。引入DorisDB之後,我們用DataX將SQL Server資料匯入DorisDB,這裡使用了DorisDB-Writer外掛,底層封裝的Stream-Load介面,向量化匯入效率非常高。MySQL可以通過外表insert into select流式匯入,也可以直接外表查詢,非常便捷。Tableau圖表秒出,體驗有了質的飛躍。
運維成本較低
資料中心是非常核心的一個線上服務,因此對高可用及靈活擴容能力有非常高的要求。DorisDB支援資料多副本,FE、BE僅僅2種角色組成的簡潔架構,在單個節點故障的時候可以保證整個叢集的高可用。另外,DorisDB在大資料規模下可以進行線上彈性擴充套件,在擴容時無Down Time,不會影響到線上業務,這個能力也是我們非常需要的。
總結
收購筆電Lenovo聯晟智達從今年(2021年)4月份開始調研DorisDB,POC測試階段用了1/4的資源,就完美替代了數十個節點的Presto叢集,當前DorisDB已經上線穩定執行。引入DorisDB後,實現了資料服務統一化,大大簡化了離線資料處理鏈路,同時也能保障查詢時延要求,之後將用來提升更多業務場景的資料服務和查詢能力。最後,感謝鼎石科技的大力支援,也期望DorisDB作為效能強悍的新一代MPP資料庫引領者越來越好!
